Intro
Getting into planner for managing the work of your teams, but you are lost in the total overview! Centralize the planning of your teams by creating them in an automated way toward a plan that will contain all teams.
Need more information about Microsoft Planner: LINK Take the chaos out of teamwork and get more done! Planner makes it easy for your team to create new plans, organize and assign tasks, share files, chat about what you’re working on, and get updates on progress.
“Work Less, Do More”
How-to?
In Planner you have for example a plan of a team and a second plan that will be the centralized plan of other teams.
Source: TEST FBI – PLANNER01
Central: TEST FBI – PLANNER02
Three buckets created, that can visualize the planning of your customers. The buckets need to be have the same name in each plan. So that a task created in bucket “BUCK01”, will be copied to the bucket “BUCK01” in the centralized plan.
So when do we start? New task has been created in the plan PLANNER 01. This will be a trigger for the Microsoft Flow. Let’s go to Flow … already we will have some exceptions in the Flow that will be explained in this blog.
Create a blank new Flow and add following trigger [When a new task is created], and select the source plan. Here PLANNER01. First some background to understand the following steps:
First some background to understand the following steps:
Buckets
You can sort the tasks into buckets to help break things up into phases, types of work, departments, or whatever makes the most sense for your plan.
The bucket has an unique bucket ID, see body output of the trigger:
{ "@odata.etag": "W/\"JzEtVGFzayAgQEBAQEBAQEBAQEBAQEBARCc=\"", "planId": "w_4V8-0QJE6Wl_TWKvRmipYAB2MC", "bucketId": "_WBroQk8R0ah-yiAl1fJfZYAPvUV", "title": "TAAK 2 - BUCK01 - FBI", "orderHint": "8586611510014671691", "assigneePriority": "8586611510014671691", "percentComplete": 0, "startDateTime": null, "createdDateTime": "2018-10-25T08:24:44.0104116Z", "dueDateTime": "2018-11-02T10:00:00Z", "hasDescription": false, "previewType": "automatic", "completedDateTime": null, "completedBy": null, "referenceCount": 0, "checklistItemCount": 0, "activeChecklistItemCount": 0, "conversationThreadId": null, "id": "LYY_3By_mUyXgqnmM7Q7S5YAG5Aj", "createdBy": { "user": { "displayName": null, "id": "ac45b0b4-1a2b-46a6-b2d3-7c4a6f4dd458" } }, "appliedCategories": {}, "assignments": { "ac45b0b4-1a2b-46a6-b2d3-7c4a6f4dd458": { "@odata.type": "#microsoft.graph.plannerAssignment", "assignedDateTime": "2018-10-25T08:24:44.0104116Z", "orderHint": "", "assignedBy": { "user": { "displayName": null, "id": "ac45b0b4-1a2b-46a6-b2d3-7c4a6f4dd458" } } } } }
The bucket id is for each plan unique. So the only way to match both buckets of each plan is the unique name “BUCK01”. So we need to have a mechanism to match the correct bucket name.
We can use the Flow action “List Bucket”
[ { "@odata.etag": "W/\"JzEtQnVja2V0QEBAQEBAQEBAQEBAQEBASCc=\"", "name": "BUCK03", "planId": "w_4V8-0QJE6Wl_TWKvRmipYAB2MC", "orderHint": "8586618331113434567P6", "id": "IRJ08qbj7kOw2tDzThTVgJYAG-Tf" }, { "@odata.etag": "W/\"JzEtQnVja2V0QEBAQEBAQEBAQEBAQEBASCc=\"", "name": "BUCK02", "planId": "w_4V8-0QJE6Wl_TWKvRmipYAB2MC", "orderHint": "I#", "id": "x_yNrLZbLEm4v0kniek0X5YAI0qi" }, { "@odata.etag": "W/\"JzEtQnVja2V0QEBAQEBAQEBAQEBAQEBASCc=\"", "name": "BUCK01", "planId": "w_4V8-0QJE6Wl_TWKvRmipYAB2MC", "orderHint": "[v", "id": "_WBroQk8R0ah-yiAl1fJfZYAPvUV" } ]
In the bucket list, we can find both values. How do we match the first bucket value id towards the name of both plans and get the bucket id of the centralized plan.
Therefore we create two variables (Type: string), one for the source bucket name and a variable for the destination (centralized plan) bucket ID.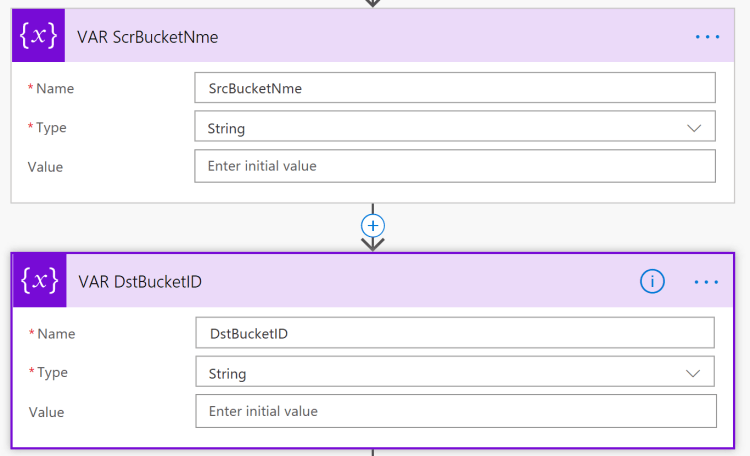 Rename the action to the appropriate description/name. Search for variable and select initialize variable.
Rename the action to the appropriate description/name. Search for variable and select initialize variable. Add two actions “List buckets”
Add two actions “List buckets”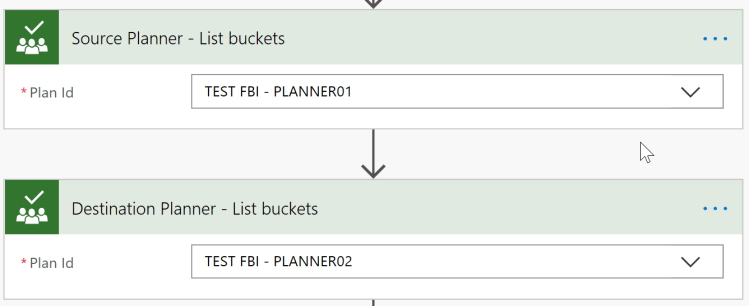
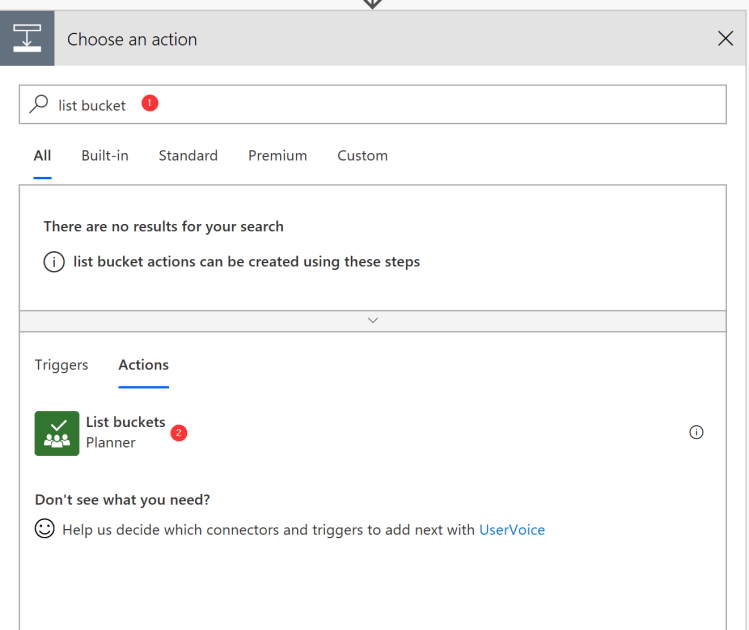
Search for action “List buckets”
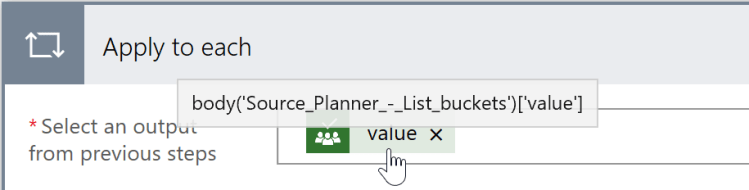
Getting the name of the unique bucket id from the trigger, can be done as follow. Compare the value of the bucket list of PLANNER01 with the body bucket id that can be found in the trigger output. Create a new action “Apply to each” and select an output of previous steps, equal to the value:
Compare the bucket id’s, by adding a “Condition” – control “is equal to”
If it’s equal we will set the variable “ScrBucketNme” to the bucket name of the source plan bucket list.
The opposite we will done, getting the bucket id of the centralized plan. Create a new action “Apply to each” and select an output of previous steps, equal to the value:

Condition has been added to get the unique bucket id of the plan PLANNER02.
It’s equal.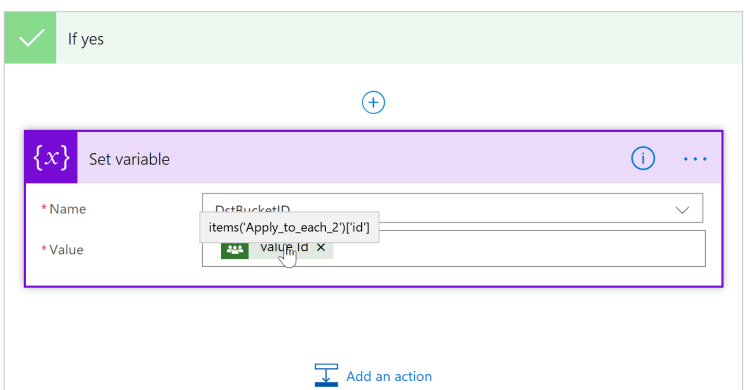
At this moment we have all the information to create a task in the centralized bucket “BUCK01”. But we need to solve still one problem. A task can be assigned to a person. But also the person has an unique ID. But this cannot be found in the standard dynamic content of the trigger “When a new task is created.”
Again the output of the trigger:
"assignments": { "ac45b0b4-1a2b-46a6-b2d3-7c4a6f4dd458": { "@odata.type": "#microsoft.graph.plannerAssignment", "assignedDateTime": "2018-10-25T08:24:44.0104116Z", "orderHint": "", "assignedBy": { "user": { "displayName": null, "id": "ac45b0b4-1a2b-46a6-b2d3-7c4a6f4dd458" }
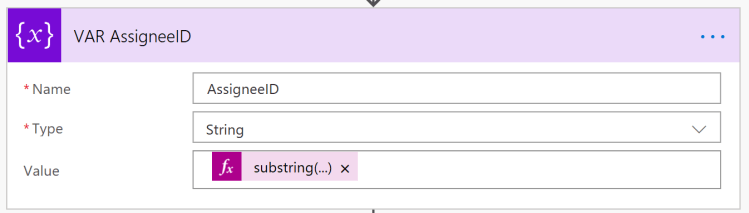
You can find the persons unique ID in the “assignments” of the JSON – output. Create an action to “Initialize variable”, here we a the following substring – expression.
SUBSTRING This function returns a subset of characters from a string. It requires 3 parameters: the string from which the substring is taken; the index where the substring begins; and the length of the substring. Last two parameters are numbers.
We need to get the information of the string “assignments” and id (2) and ac45b0b4-1a2b-46a6-b2d3-7c4a6f4dd458 (36)
substring(string(triggerBody()?['assignments']), 2, 36)
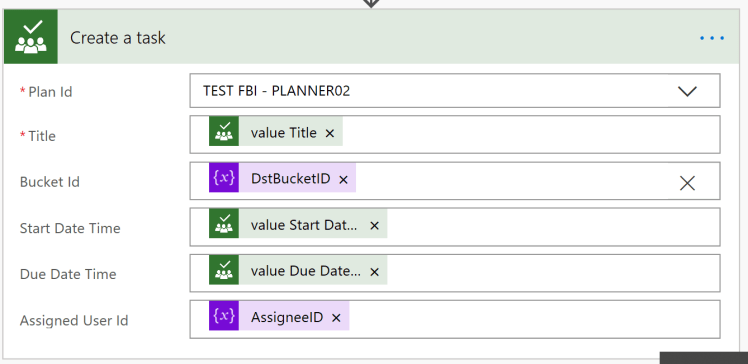
Do we have everything, Yes! We can create the task in the centralized plan in the correct bucket, equal to the source bucket name.
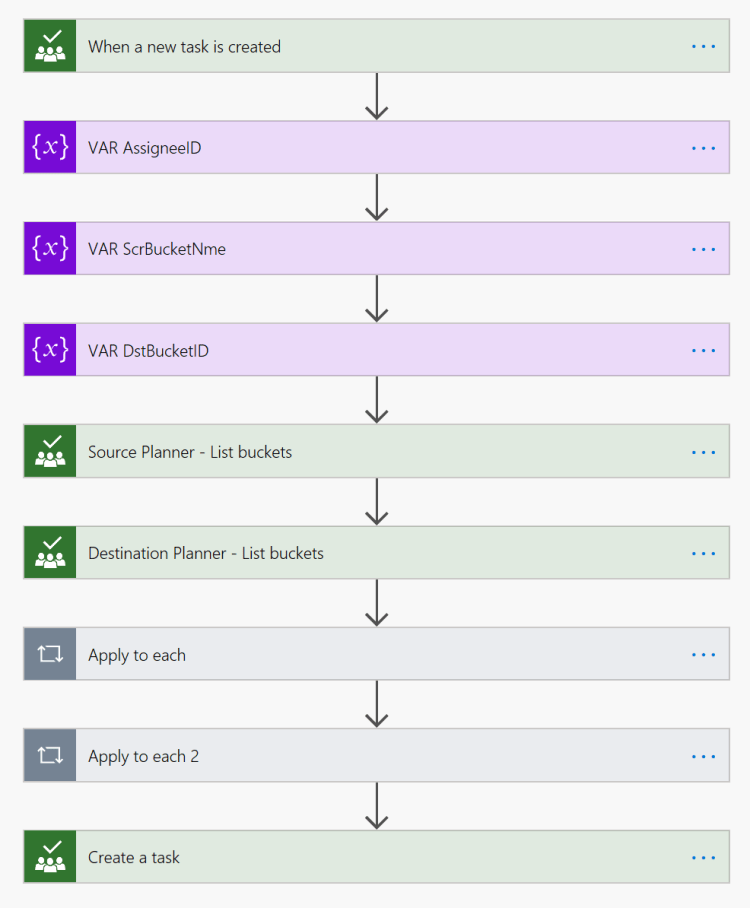
Complete overview of the flow:
This will result in the following output in Planner.
Enjoy! Feedback is welcome.
Would you like more of these Flow examples? Suggestions are welcome ...
