Power Platform Dataflows are a powerful feature that allows users to extract, transform, and load data (ETL) from various sources into central data storage. Just a type of central data storage can be Dataverse or Data lake. This central data storage can power business intelligence and analytics tools, such as Power BI and Azure Synapse, to gain insights and make data-driven decisions.
One of the key benefits of using Power Platform Dataflows is that they allow users to easily connect to a wide range of data sources, including popular databases, SaaS applications, and flat files. This means that users can easily extract data from multiple sources and bring it into a single location, allowing them to easily merge, use and analyze data from different systems.
In addition to extracting data, Power Platform Dataflows also allow users to transform the data as it is being loaded into the Data Lake. This can include cleaning and normalizing the data and transformations. These transformations can be performed using a simple, drag-and-drop interface, making it easy for users with little or no coding experience to manipulate data.
Another advantage of Power Platform Dataflows is that they can be scheduled to run regularly and put data in the destination source, so it is always up-to-date. This allows users to build reports and dashboards that are always based on the most current data, enabling them to make more informed decisions.
Have a look at the performance of a Power Platform Dataflow.
What are the limits of Power Platform Dataflows? What will happen when we import CSV files of 100, 1000, 5000, 10000, and 50000 lines of data. The test was done in a developer environment, and the same columns were uploaded without additional data optimisation and import functionalities.
CSV Lines
Time to import the data
Comments
100
96 seconds
No additional remarks were found during the data import to a new table.
1000
94 seconds
No additional remarks were found during the data import to a new table.
5000
134 seconds
No additional remarks were found during the data import to a new table.
10000
528 seconds
No additional remarks were found during the data import to a new table.
50000
1620 seconds
No additional remarks were found during the data import to a new table.
The performance of Power Platform Dataflows will depend on several factors, including the size and complexity of the data being processed and the number and complexity of the transformations being applied. Looking at the result in the graph, we can see that the performance is acceptable for uploads until 5000 records. As from 5000 records, the upload times our rising exponentially.
Here are a few tips for optimizing the performance of your Dataflows:
Use incremental refresh: Incremental refresh allows you to only load new or modified records into your data store rather than re-processing the entire dataset each time. This can significantly reduce the time and resources required to refresh your data.
Use the correct data type: Using the appropriate data type for each column in your Dataflow can help improve performance. For example, a “whole number” data type for columns containing only whole numbers will be faster than a “decimal number” data type.
Limit the number of records to 5000 for a good performance.
Overall, it is essential to regularly monitor the performance of your Dataflows and make adjustments as needed to ensure that they run efficiently.
Let’s have a look at three examples of Dataflows. The first example shows you to build and simple CSV file import towards a new table, and the second is a simple CSV file import to an existing table in Dataverse. The last example will guide you throw the import of data in Dataverse related to a Lookup table via Dataflows.
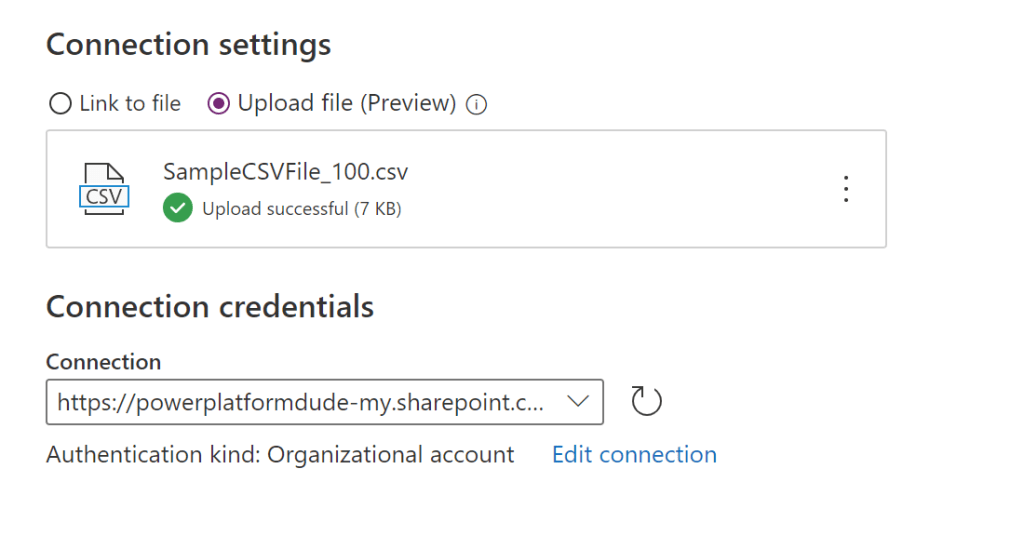
Example 01 – Simple CSV file import towards a new table. In this example, the Dataflow will create the table in Dataverse and import the data from a CSV file (around 100 lines of data).
Upload File (Preview)
The files our uploaded to you personal Microsoft OneDrive under “Uploaded Files”
Example 02 – Simple CSV file import towards an existing table.
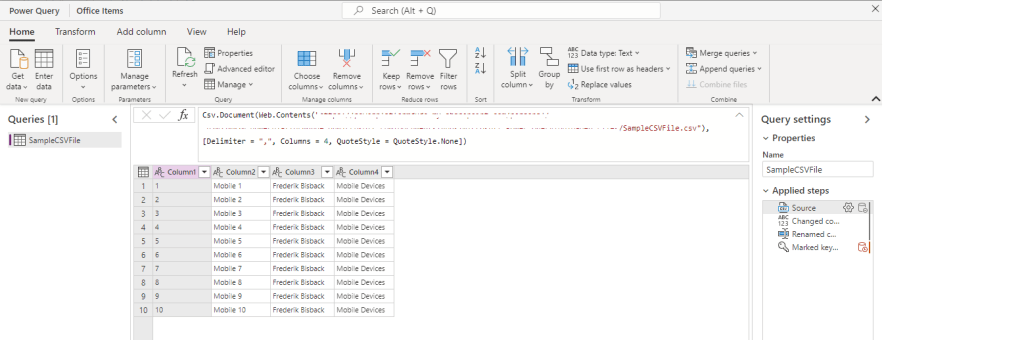
In this example, the Dataflow will import the data from a CSV file in an existing table (around 100 lines). The existing table has been created upfront and has the following columns. Primary column Item, Designer and Type.
You can specify whether records are created or upserted (updated) in a dataflow. How do we control this? Each time you refresh a dataflow, it will fetch records from the source and load them into Dataverse. If you run the dataflow more than once—depending on how you configure the dataflow—you can:
Create new records for each dataflow refresh, even if such records exist in the destination table.
Create new records if they don’t already exist in the table, or update existing records if they already exist in the table. This behaviour is called upsert.
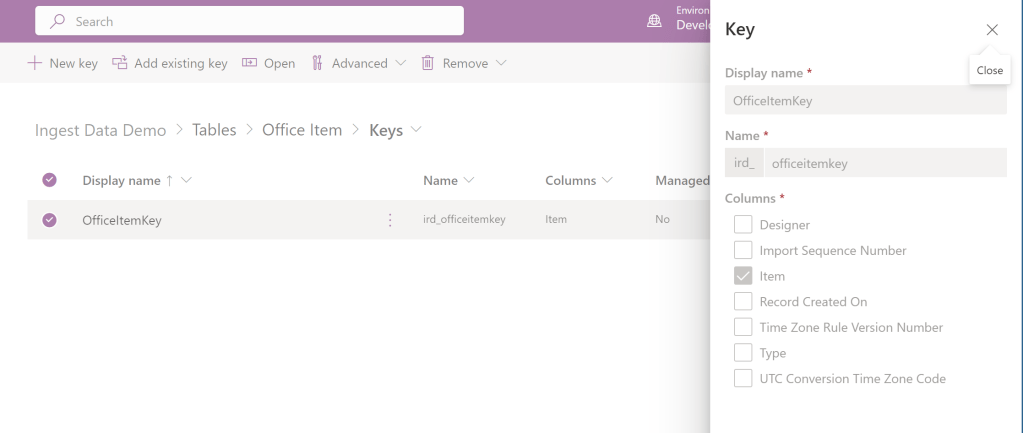
A key column will indicate to the dataflow to upsert records into the destination table, while not selecting a key will always create new records in the destination table.
A key column is a column that’s unique and deterministic of a data row in the table. For example, in his, the Item is a critical column in an Office Item table. You shouldn’t have two rows with the same Item. Also, one item with the value “Xerox 1904″—should only represent one row in the table. To choose the key column for the table in Dataverse from the dataflow, you need to set the key field in the tables.
An alternate key has been created for the item column. The primary name field is a display field used in Dataverse. This field is used in default views to show the content of the table in other applications. This field isn’t the primary key field and shouldn’t be considered as that. This field can have duplicates because it’s a display field. The best practice, however, is to use a concatenated field to map to the primary name field, so the name is fully explanatory. The alternate key field is what is used as the primary key.
Start to create a Dataflow to import the data. See the same steps as Example 01. See the video.
Select the location of the file that contains the data.
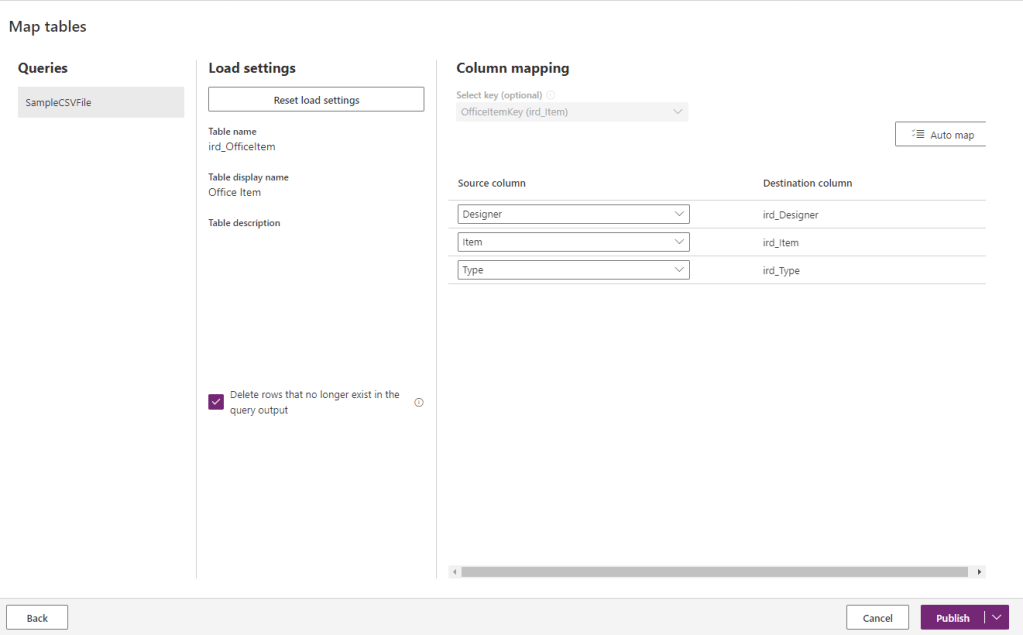
Map the source columns to the destination columns and publish the dataflow. This will show up as follows in the My Dataflows view. Now you can run and upload data to the Dataverse table.
We can also plan a refresh and incremental refresh. So that update will be added automatically based on the schedule of the Dataflows. A planned refresh is refreshing the data source completely, meaning that the values will be overwritten by the new data in the data source. Incremental refresh will allow you to update only data from a specific time window.
Example 03 – CSV file import towards an existing table of data in Dataverse related to a Lookup table via Dataflows
In this example, I will guide you through a data import in Dataverse with data related to a lookup table. The example contains an “injury types” table with prepopulated values. See the screenshot below:
Uploading data from the source data must be included in the lookup table. When not, the upload will fail.
Result
Overall, Power Platform Dataflows provide a powerful and flexible way for users to extract, transform, and load data (ETL) from various sources into Dataverse or Azure Data Lake, enabling them to easily merge and analyze data from different systems and make data-driven decisions. Whether you are a business analyst, data scientist, or developer, Power Platform Dataflows can help you unlock the power of data to drive better business outcomes.
If you like this blog. Please give me a dumbs up, share the blog or leave comments below.






Thanks for sharing.
LikeLike